Binary Lifting - An Interesting Dynamic Programming Technique
I recently encountered a very interesting question on leetcode that has taught me a new algorithmic skill to add to my toolbelt. As the title of this post suggests, the algorithm is called binary lifting and it is by no means trivial. Regardless I thought it was a very nice algorithm and I wanted to share it.
The problem description
The Leetcode problem that I’m referring to is: “1483. Kth Ancestor of a Tree Node”. The problem statement is as follows:
You are given a tree with n nodes numbered from 0 to n-1 in the form of a parent array where parent[i] is the parent of node i. The root of the tree is node 0. Implement the function
getKthAncestor(int node, int k)
to return the k-th ancestor of the given node. If there is no such ancestor, return -1.The k-th ancestor of a tree node is the k-th node in the path from that node to the root.
A Naive Solution
How can we solve this problem naively? The first thing that comes to mind is to create a tree structure and to store a parent pointer in each node. In addition store the nodes in a HashSet for quick retrieval. When a query comes for a node N, find that node in the hash set, and traverse its parent k times or until we traverse past the root node in which case we return -1. What is the complexity of this algorithm? We will assume for the purpose of this exercise that building the tree is a one-time operation which we can do as a preprocessing step. So the only cost of the algorithm is the parent’s traversal which is O(K).
What can we do better?
To understand what we can do better we need to start with some basics. The first is the idea that every natural number N can be represented as a sum of powers of 2. For example 7 = 4 + 2 + 1, 13 = 8 + 4 + 1, 101 = 64 + 32 + 4 + 1. Let's prove this mathematically. We will use induction for this. We want to prove that for any natural number N, it can be represented as a sum of powers of 2:
- Base Case: $N = 1$
- Inductive Step: Let's assume that this claim is true for any $n < N$, and prove for N (which is not a power-of-two).
- case 1: N is a power-of-two. We are done.
- case 2: N is not a power-of-two. Let $k$ be the largest number such that $2^k < N$. Hence $N- {2^k} <N$. Based on our hypothesis it can be represented as a sum of powers of two. Let that sum equal S. We then have $N = S + 2^k$ which is a summation of powers of 2.
Why is this useful? because we can find the K’th ancestor of a node by traversing ancestors which are powers of 2 away from that node until we reach the K’th ancestor. how many are there? the answer is Log(K). Any number K can be represented with $log(K)$ bits. Those bits correspond to a sum of powers of 2. So by this small shift in our perception, we can reduce our run time from $O(K)$ to $O(log(K))$. This is precisely what binary lifting is.
Prerequisites
The devil is as usual in the details. In this case, we need to figure out how to calculate those powers of 2’s that will lead us to find the K’th ancestor quickly. Fortunately, we can leverage the fact that any precomputation we do does not count towards our overall runtime. After all, if we need to query for the Kth ancestor one million times, then that pre-computation will be paid in full. An interesting observation that will help us is the following:
$2^n = 2*2^{n-1} = {1 + 1}*2 ^ {n-1} = 2^{n-1} + 2^{n-1}$
We are left with: $2^n = 2^{n-1} + 2^{n-1}$
How is this helpful? the N’th power of two can be found by looking at the $N -1$ power of 2 twice. More precisely, finding the $2 ^ N$ ancestor of a node is the same as finding its $2 ^ {N-1}$ ancestor denoted by N1, and then finding N1’s $2 ^ {N-1}$ ancestor. Did anyone spot the recursive relationship here? did you spot the reoccurring subproblems? What method would allow us to exploit this recursive reoccurring structure? The answer is Dynamic Programming.
The recursive formula:
Denote $$DP[N][J] = \text{the Jth power of two ancestor of the N’th node.}$$
$$
DP[N][J] =
Parent[N] \quad \text{if } J = 1 \
DP[DP[N][J-1]][J-1] \quad \text{otherwise}
$$
In other words, if $J$ is 1 we go directly to our parent. If it is not, we first lookup the ancestor corresponding to $2^{j-1}$, and then look up its $2^{j-1}$ ancestor.
This is exactly equivalent to the formula we wrote before. Except now we are storing it in a tabular manner which will allow us to quickly locate the Jth power-of-two ancestor of a given node.
The Algorithm
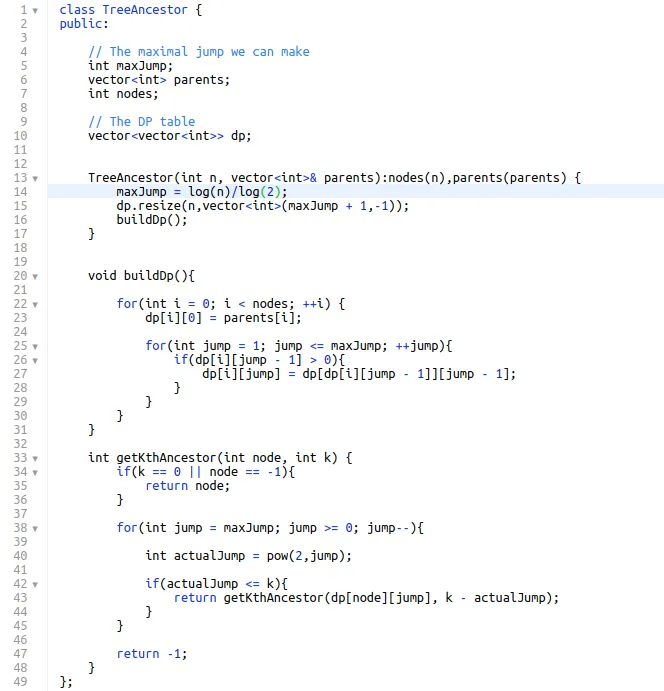
Now we’re finally ready to look at the algorithm for this problem. Before I paste the code, let's talk about how it's going to look like. We will start by first calculating the maximal power of 2 that we will need. Remember that the nodes are numbers between 0 to N-1 so we can easily find that maximal power of 2 by taking the $log2$ of N (the number of nodes). Then we’ll create our DP table as shown above. This will be done in the constructor of our class. We will traverse the nodes in order 0 through N-1 and for each one we will store all its power-of-2 ancestors. Notice that we will be taking advantage of the fact that parents (or ancestors) have smaller node Ids than their children.
The root node will have all its ancestors be set to -1. Once we have the table ready we can move on to our primary method getKthAncestor. This will be a recursive method that will use our precomputed DP table. Given K (the parameter of our method) we will find the greatest jump such that $2 ^ {jump}≤ K$. denote that ancestor as T. We will then recurse for T and with an ancestor $K- {2^{jump}}$. You should not be surprised by this, as it maps completely to our induction proof.
The Code (C++)
Summary
We have now seen how binary lifting can be used to find the Kth ancestor of a node in a tree. This is a very powerful technique that can be used to solve a variety of problems. The key idea is to precompute the ancestors of each node in a table and then use that table to quickly find the Kth ancestor of a node. This technique has a time complexity of $O(N log N)$ for the precomputation and O(log K) for each query, making it a very efficient algorithm.
Comments
Leave a Comment
Comments (0)